Language :

The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale for AI, data analytics, and high-performance computing (HPC) to tackle the world’s toughest computing challenges.
The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale for AI, data analytics, and high-performance computing (HPC) to tackle the world’s toughest computing challenges. As the engine of the NVIDIA data center platform, A100 can efficiently scale to thousands of GPUs or, with NVIDIA Multi-Instance GPU (MIG) technology, be partitioned into seven GPU instances to accelerate workloads of all sizes. And third-generation Tensor Cores accelerate every precision for diverse workloads, speeding time to insight and time to market.
A100 is part of the complete NVIDIA data center solution that incorporates building blocks across hardware, networking, software, libraries, and optimized AI models and applications from NGC™. Representing the most powerful end-to-end AI and HPC platform for data centers, it allows researchers to deliver real-world results and deploy solutions into production at scale.
AI networks are big, having millions to billions of parameters. Not all of these parameters are needed for accurate predictions, and some can be converted to zeros to make the models “sparse” without compromising accuracy. Tensor Cores in A100 can provide up to 2X higher performance for sparse models. While the sparsity feature more readily benefits AI inference, it can also improve the performance of model training.
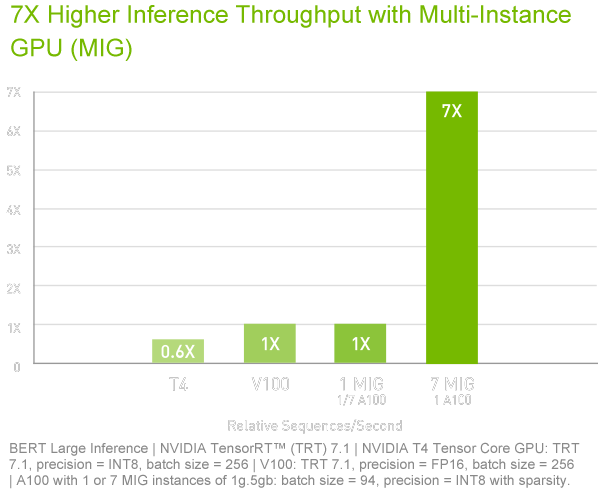
An A100 GPU can be partitioned into as many as seven GPU instances, fully isolated at the hardware level with their own high-bandwidth memory, cache, and compute cores. MIG gives developers access to breakthrough acceleration for all their applications, and IT administrators can offer rightsized GPU acceleration for every job, optimizing utilization and expanding access to every user and application.
A100 accelerates workloads big and small. Whether using MIG to partition an A100 GPU into smaller instances, or NVLink to connect multiple GPUs to accelerate large-scale workloads, A100 can readily handle different sized acceleration needs, from the smallest job to the biggest multi-node workload. A100’s versatility means IT managers can maximize the utility of every GPU in their data center around the clock.
NVIDIA NVLink in A100 delivers 2X higher throughput compared to the previous generation. When combined with NVIDIA NVSwitch™, up to 16 A100 GPUs can be interconnected at up to 600 gigabytes per second (GB/ sec) to unleash the highest application performance possible on a single server. NVLink is available in A100 SXM GPUs via HGX A100 server boards and in PCIe GPUs via an NVLink Bridge for up to 2 GPUs.
A100 delivers 312 teraFLOPS (TFLOPS) of deep learning performance. That’s 20X Tensor FLOPS for deep learning training and 20X Tensor TOPS for deep learning inference compared to NVIDIA Volta™ GPUs.
With 40 gigabytes (GB) of high bandwidth memory (HBM2), A100 delivers improved raw bandwidth of 1.6TB/sec, as well as higher dynamic random-access memory (DRAM) utilization efficiency at 95 percent. A100 delivers 1.7X higher memory bandwidth over the previous generation.
AI models are exploding in complexity as they take on next-level challenges such as conversational AI. Training them requires massive compute power and scalability.
NVIDIA A100 Tensor Cores with Tensor Float (TF32) provide up to 20X higher performance over the NVIDIA Volta with zero code changes and an additional 2X boost with automatic mixed precision and FP16. When combined with NVIDIA® NVLink®, NVIDIA NVSwitch™, PCI Gen4, NVIDIA® Mellanox® InfiniBand®, and the NVIDIA Magnum IO™ SDK, it’s possible to scale to thousands of A100 GPUs.
A training workload like BERT can be solved at scale in under a minute by 2,048 A100 GPUs, a world record for time to solution.
For the largest models with massive data tables like deep learning recommendation models (DLRM), A100 80GB reaches up to 1.3 TB of unified memory per node and delivers up to a 3X throughput increase over A100 40GB.
NVIDIA’s leadership in MLPerf, setting multiple performance records in the industry-wide benchmark for AI training.
A100 introduces groundbreaking features to optimize inference workloads. It accelerates a full range of precision, from FP32 to INT4. Multi-Instance GPU (MIG) technology lets multiple networks operate simultaneously on a single A100 for optimal utilization of compute resources. And structural sparsity support delivers up to 2X more performance on top of A100’s other inference performance gains.
On state-of-the-art conversational AI models like BERT, A100 accelerates inference throughput up to 249X over CPUs.
On the most complex models that are batch-size constrained like RNN-T for automatic speech recognition, A100 80GB’s increased memory capacity doubles the size of each MIG and delivers up to 1.25X higher throughput over A100 40GB.
NVIDIA’s market-leading performance was demonstrated in MLPerf Inference. A100 brings 20X more performance to further extend that leadership.
To unlock next-generation discoveries, scientists look to simulations to better understand the world around us.
NVIDIA A100 introduces double precision Tensor Cores to deliver the biggest leap in HPC performance since the introduction of GPUs. Combined with 80GB of the fastest GPU memory, researchers can reduce a 10-hour, double-precision simulation to under four hours on A100. HPC applications can also leverage TF32 to achieve up to 11X higher throughput for single-precision, dense matrix-multiply operations.
For the HPC applications with the largest datasets, A100 80GB’s additional memory delivers up to a 2X throughput increase with Quantum Espresso, a materials simulation. This massive memory and unprecedented memory bandwidth makes the A100 80GB the ideal platform for next-generation workloads.
Data scientists need to be able to analyze, visualize, and turn massive datasets into insights. But scale-out solutions are often bogged down by datasets scattered across multiple servers.
Accelerated servers with A100 provide the needed compute power—along with massive memory, over 2 TB/sec of memory bandwidth, and scalability with NVIDIA® NVLink® and NVSwitch™, —to tackle these workloads. Combined with InfiniBand, NVIDIA Magnum IO™ and the RAPIDS™ suite of open-source libraries, including the RAPIDS Accelerator for Apache Spark for GPU-accelerated data analytics, the NVIDIA data center platform accelerates these huge workloads at unprecedented levels of performance and efficiency.
On a big data analytics benchmark, A100 80GB delivered insights with 83X higher throughput than CPUs and a 2X increase over A100 40GB, making it ideally suited for emerging workloads with exploding dataset sizes.
A100 with MIG maximizes the utilization of GPU-accelerated infrastructure. With MIG, an A100 GPU can be partitioned into as many as seven independent instances, giving multiple users access to GPU acceleration. With A100 40GB, each MIG instance can be allocated up to 5GB, and with A100 80GB’s increased memory capacity, that size is doubled to 10GB.
MIG works with Kubernetes, containers, and hypervisor-based server virtualization. MIG lets infrastructure managers offer a right-sized GPU with guaranteed quality of service (QoS) for every job, extending the reach of accelerated computing resources to every user.
The platform accelerates over 700 HPC applications and every major deep learning framework. It’s available everywhere, from desktops to servers to cloud services, delivering both dramatic performance gains and cost-saving opportunities.

| NVIDIA A100 for PCIe | |
| GPU Architecture | NVIDIA Ampere |
| Peak FP64 | 9.7 TF |
| Peak FP64 Tensor Core | 19.5 TF |
| Peak FP32 | 19.5 TF |
| Peak TF32 Tensor Core | 156 TF | 312 TF* |
| Peak BFLOAT16 Tensor Core | 312 TF | 624 TF* |
| Peak FP16 Tensor Core | 312 TF | 624 TF* |
| Peak INT8 Tensor Core | 624 TOPS | 1,248 TOPS* |
| Peak INT4 Tensor Core | 1,248 TOPS | 2,496 TOPS* |
| GPU Memory | 40 GB |
| GPU Memory Bandwidth | 1,555 GB/s |
| Interconnect | NVIDIA NVLink 600 GB/s** PCIe Gen4 64 GB/s |
| Multi-instance GPUs | Various instance sizes with up to 7MIGs @5GB |
| Form Factor | PCIe |
| Max TDP Power | 250W |
| Delivered Performance of Top Apps | 90% |
* With sparsity
** SXM GPUs via HGX A100 server boards, PCIe GPUs via NVLink Bridge for up to 2-GPUs
Future







{kind=link}