言語 :

NVIDIA H100 Tensor コアGPUを使用して、あらゆるワークロードでかつてない性能、拡張性、セキュリティを活用してください。With NVIDIA® NVLink® スイッチ システムを使用すると、最大256台のH100を接続して、エクサスケールのワークロードを高速化でき、専用のTransformer Engineで、1兆単位のパラメーターの言語モデルを実装することができます。H100の複合的な技術革新により、大規模な言語モデルを前世代のよりも30倍も高速化し、業界をリードする対話型AIを実現することができます。
メインストリームである標準サーバー向けのH100には、NVIDIA AI Enterpriseソフトウェア スイートのサブスクリプション 5 年分 (エンタープライズ サポートなど) が付属しており、その非常に優れた性能によってAIを簡単に導入することができます。それにより、企業や組織は、AI チャットボット、レコメンデーション エンジン、ビジョン AIなど、H100で高速化する AI ワークフローを構築するために必要な AIフレームワークおよびツールが活用できるようになります。
混合エキスパート (3950 億個のパラメーター)
H100 は第 4 世代の Tensor コアと、FP8 精度で混合エキスパート(MoE)モデルのトレーニングを前世代よりも最大9倍高速化するTransformer Engine を備えています。GPUとGPU を毎秒900ギガバイトで相互接続する第4世代 NVLink、ノード全体で GPUごとに通信を高速化する NVLINK Switch System、PCIe Gen5、NVIDIA Magnum IO™ ソフトウェアの組み合わせによって、小規模なエンタープライズから大規模な統合 GPU クラスターまで効率的なスケーラビリティを提供します。
データ センター規模での H100 GPU 導入は卓越したパフォーマンスを実現し、あらゆる研究者に次世代のエクサスケール ハイパフォーマンス コンピューティング (HPC) と1兆単位のパラメーターAIをもたらします。
AI は、様々なビジネスの課題を、同じくらい様々なニューラル ネットワークを使用して解決します。優れたAI推論アクセラレータには、最高のパフォーマンスの提供だけでなく、様々なネットワークを加速するための多様性も求められます。
H100では、市場をリードする NVIDIA の推論リーダーシップをさらに拡張し、推論が最大30 倍高速化になる、レイテンシが最小限に抑えられるなど、機能が強化されています。第4世代のTensorコアは FP64、TF32、FP32、FP16、INT8 など、あらゆる精度を高速化し、Transformer Engineは、FP8とFP16の両方を活用してメモリ消費を削減し、パフォーマンスを向上させながら、大規模な言語モデルの精度を維持します。
Megatron チャットボット推論 (5300 億個のパラメーター)
NVIDIA データ センター プラットフォームは、ムーアの法則を超えるパフォーマンス向上を継続的に提供します。また、H100の新しい画期的なAI機能は、「HPC+AI」のパワーをさらに増幅し、世界の最重要課題の解決に取り組む科学者や研究者にとって、発見までの時間を短縮します。
H100 は、倍精度Tensorコアの毎秒浮動小数点演算(FLOPS)を3倍にし、HPCで60 teraFLOPSのFP64コンピューティングを実現します。AIと融合したHPCアプリケーションでは、H100のTF32精度を活用し、コード変更なしに、単精度の行列乗算演算で 1petaFLOPのスループットを達成することができます。
また、H100はDPX命令を備え、NVIDIA A100 TensorコアGPUの7倍のパフォーマンスを提供し、DNAシーケンス アライメント用のSmith-Watermanなど、動的プログラミング アルゴリズムにおいて従来のデュアルソケットCPUのみのサーバーと比較して、40倍の高速化を実現します。
AI アプリケーションの開発では、データ分析に多くの時間を費やします。大規模なデータセットは、複数のサーバーに分散されるため、汎用の CPU のみのサーバーを使用したスケールアウト ソリューションは、スケーラブルなコンピューティング パフォーマンスの欠如によって行き詰まります。
H100 を搭載した高速サーバーは、GPU あたり3テラバイト/秒 (TB/s) のメモリ帯域幅とNVLinkおよびNVSwitch によるスケーラビリティに加えて、コンピューティング能力を提供し、大規模なデータセットをサポートするための高いパフォーマンスとスケーリングでデータ分析に取り組みます。NVIDIA Quantum-2 Infiniband、Magnum IOソフトウェア、GPU 高速化 Spark 3.0、NVIDIA RAPIDS™ と組み合わせることで、NVIDIA データ センター プラットフォームは、比類のないレベルのパフォーマンスと効率性でこれらの膨大なワークロードを、他にはない独自の方法で、高速化できます。
ITマネージャーは、データ センターでコンピューティング リソースの使用率 (ピークと平均の両方) を最大化することを求めます。多くの場合、コンピューティングを動的に再構成し、使用中のワークロードに合わせてリソースを適切なサイズに変更します。
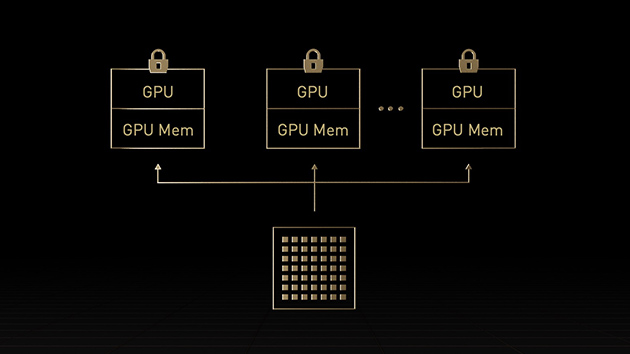
H100 の第2世代 マルチ インスタンス GPU (MIG) では、最大7個ものインスタンスに分割することで各GPUの使用率を最大化します。コンフィデンシャル コンピューティング対応のH100では、マルチテナントをエンドツーエンドで安全に利用できるので、クラウド サービス プロバイダー (CSP) 環境に最適です。
H100とMIG なら、インフラストラクチャ管理者は GPUアクセラレーテッド インフラストラクチャを標準化できて、同時に、GPU リソースを非常に細かくプロビジョニングして、適切な量のアクセラレーテッド コンピューティングを開発者に安全に提供し、すべての GPU リソースの使用を最適化する柔軟性を得ることができます。
今日のコンフィデンシャル コンピューティング ソリューションは CPU ベースで、AI や HPC など、大量の計算処理を必要とするワークロードの場合、十分ではありません。NVIDIA コンフィデンシャル コンピューティングは NVIDIA Hopper™ アーキテクチャの組み込みセキュリティ機能です。H100 を、コンフィデンシャル コンピューティング機能のある世界初のアクセラレータにしたのがこのアーキテクチャです。ユーザーは使用中のデータとアプリケーションの機密性と完全性を保護し、同時に、H100 GPU の卓越した高速化を利用できます。ハードウェアベースの TEE (Trusted Execution Environment/信頼できる実行環境) を作り、1 個の H100 GPU で、1 個のノード内の複数の H100 GPU で、または個々の MIG インスタンスで実行されるワークロード全体をセキュリティで保護し、隔離します。GPU で高速化するアプリケーションは、何も変更せずに TEE 内で実行できます。また、分割する必要がありません。ユーザーは AI と HPC のための NVIDIA ソフトウェアのパワーと、NVIDIA コンフィデンシャル コンピューティングから与えられるハードウェア RoT (Root of Trust/信頼の起点) のセキュリティを組み合わせることができます。
Hopper Tensor コア GPU は、テラバイト規模のアクセラレーテッド コンピューティングのために開発された NVIDIA Grace Hopper CPU+GPU アーキテクチャのパワーとなります。大規模モデルの AI と HPC で 10 倍のパフォーマンスを実現します。NVIDIA Grace CPU は Arm® アーキテクチャの柔軟性を活用するものです。アクセラレーテッド コンピューティングのために CPU とサーバーのアーキテクチャをゼロから設計できます。Hopper GPU は NVIDIA の超高速チップ間相互接続で Grace CPU とペアリングされます。毎秒 900GB の帯域幅が与えられ、PCIe Gen5 と比較して 7 倍の速さになります。この革新的な設計によって、現行で最速のサーバーと比較し、GPU への合計システムメモリ帯域幅が最大 30 倍になります。パフォーマンスは最大 10 倍になり、テラバイト単位のデータをアプリケーションで実行できます。

| FP64 | 26 TFLOPS |
| FP64 Tensor コア | 51 TFLOPS |
| FP32 | 51 TFLOPS |
| TF32 Tensor コア | 756 TFLOPS* |
| BFLOAT16 Tensor コア | 1,513 TFLOPS* |
| FP16 Tensor コア | 1,513 TFLOPS* |
| FP8 Tensor コア | 3,026 TFLOPS* |
| INT8 Tensor コア | 3,026 TOPS* |
| GPU メモリ | 80GB |
| GPU メモリ 帯域幅 | 2TB/s |
| デコーダ | 7 NVDEC 7 JPEG |
| 最大熱設計電力 (TDP) | 300-350W (構成可能) |
| マルチ インスタンス GPU | 最大 7 MIGS @ 各10GB |
| フォームファクタ |
PCIe デュアル スロット (空冷) |
| 相互接続 | NVLink:600GB/秒、PCIe Gen5:128GB/秒 |
| サーバー オプション | 1~8台のGPUを搭載した NVIDIA 認定システム |
| NVIDIA AI Entrprise | 含む |
* 疎性あり。仕様は疎性なしで半減します。
展望









{kind=link}