語系 :

NVIDIA A100 Tensor核心GPU為各種規模的人工智慧、資料分析和高效能運算(HPC)作業提供前所未有的加速能力,以解決全球最嚴苛的運算挑戰。
NVIDIA A100 Tensor 核心 GPU 為各種規模的作業提供前所未有的加速能力,可強化全球效能最高的彈性資料中心,支援人工智慧、資料分析和高效能運算。A100 採用 NVIDIA Ampere 架構,為 NVIDIA 資料中心平台的引擎。A100 提供的效能比前一代高 20 倍,還可以分割成 7 個 GPU 執行個體,根據不斷變化的需求進行動態調整。A100 提供 40 GB 和 80 GB 的記憶體版本,並在 80 GB 版本上首度推出全球最快速的記憶體頻寬,每秒超過 2 TB (TB/秒),可解決最大的模型和資料集。
NVIDIA A100 產品型錄(PDF 612KB)
A100 80GB PCIe 產品簡介(PDF 380KB)
A100 40GB PCIe 產品簡介(PDF 332KB)
人工智慧網絡很龐大,擁有數百萬至數十億個參數。並非所有的參數都需要用於做準確的預測,可以將某些參數轉換為零以使模型「稀疏」而不會影響準確性。
A100中的Tensor Core可以為稀疏模型提供高達2倍的效能。雖然稀疏性功能更容易使AI推論受益,但它也可以提高模型訓練的效能。
一個A100 GPU可以劃分為多達七個GPU應用個體,它們在硬件層完全隔離,並擁有專屬的高頻寬記憶體,緩衝記憶體和運算核心。多執行個體 GPU(MIG)為開發人員提供了針對其所有應用程式的突破性加速功能,IT管理員可以為每個作業提供適當大小的GPU加速功能,從而優化利用率並擴展對每個用戶和應用程式的使用權限。
A100 是 NVIDIA 資料中心的一部份,完整的解決方案包含硬體、網路、軟體、函式庫的建置組塊,以及 NGC™ 上的最佳化人工智慧模型和應用程式。其代表最強大的資料中心端對端人工智慧和高效能運算平台,讓研究人員能快速產出實際成果,並將解決方案大規模部署到生產環境中。
隨著人工智慧模型處理更高一級的挑戰 (如對話式人工智慧),其複雜度也急遽增長。訓練模型需要極強大的運算和擴充能力。
若使用精度為 Tensor Float (TF32) 的 NVIDIA A100 Tensor 核心,可在完全不變更程式碼的情況下,提供比 NVIDIA Volta 高 20 倍的效能,若使用自動混合精度和 FP16,還可進一步提高 2 倍。與 NVIDIA® NVLink®、NVIDIA NVSwitch™、第四代 PCI、NVIDIA® InfiniBand® 和 NVIDIA Magnum IO™ SDK 搭配使用時,還可以擴充到使用數千個 A100 GPU。
像是 BERT 這類的訓練工作負載,可在一分鐘內以 2,048 個 A100 GPU 大規模處理,創下全球獲得解決方案的最短時間記錄。
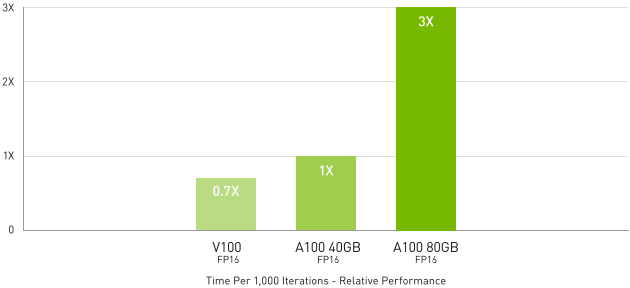
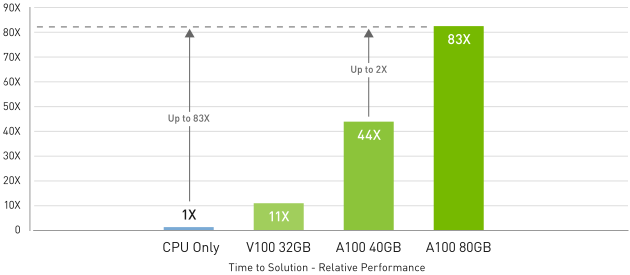
對於具有大型資料表格的最大模型,如用於推薦系統的深度學習建議模型 (DLRM),A100 80 GB 每個節點最多可達到 1.3 TB 的整合記憶體,並提供比 A100 40 GB 多達 3 倍的輸送量。
MLPerf 在人工智慧訓練業界級的基準測試中,創下多項效能記錄,完整體現 NVIDIA 的業界領先地位。
DLRM 訓練
DLRM on HugeCTR framework, precision = FP16 | NVIDIA A100 80GB batch size = 48 | NVIDIA A100 40GB batch size = 32 | NVIDIA V100 32GB batch size = 32。
A100 帶來創新功能以最佳化推論工作負載。從 FP32 到 INT4,加速整個精度範圍。多執行個體 GPU (MIG) 技術可讓多個網路在單一 A100 上同時運作,以最佳方式使用運算資源。除了 A100 提升的其他推論效能以外,支援結構化稀疏可提供高達 2 倍的效能。
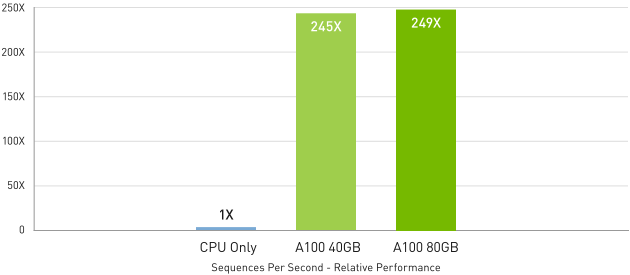
在 BERT 等先進對話式人工智慧模型中,A100 可加速的推論輸送量是 CPU 的 249 倍。
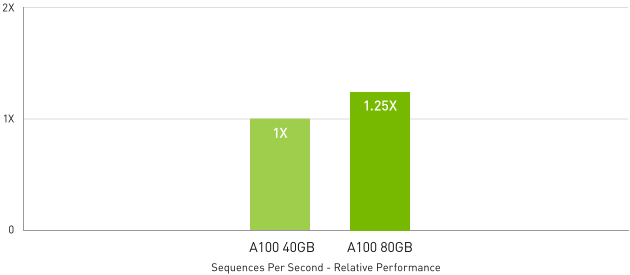
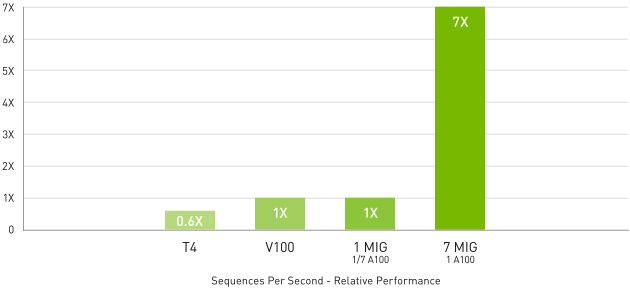
在批次大小受到限制的高度複雜模型 (如 RNN-T) 中,為了提供自動語音辨識功能,A100 80 GB 增加的記憶體容量會將每個 MIG 的大小加倍,並提供比 A100 40 GB 高 1.25 倍的輸送量。
NVIDIA 領先業界的效能已在 MLPerf 推論中得到證實。A100 提供的 20 倍效能將進一步擴大 NVIDIA 的領先地位。
BERT 大型推論
BERT-Large Inference | CPU only: Dual Xeon Gold 6240 @ 2.60 GHz, precision = FP32, batch size = 128 | V100:NVIDIA TensorRT™ (TRT) 7.2, precision = INT8, batch size = 256 | A100 40GB and 80GB, batch size = 256, precision = INT8,具稀疏性。
RNN-T 推論:單一串流
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16。
為了推進新一代發現成果,科學家需要模擬技術以更透徹地瞭解我們周圍的世界。
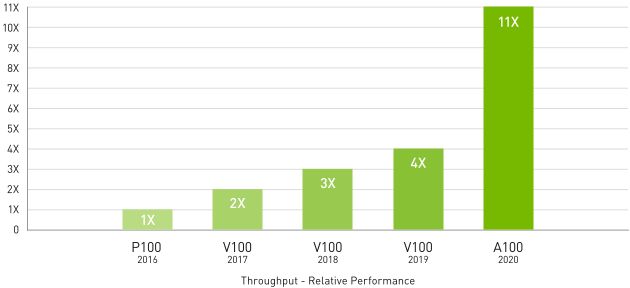
自 GPU 問世以來,NVIDIA A100 帶來的雙精度 Tensor 核心是高效能運算領域中的最大進展。 搭配 80 GB 速度最快的 GPU 記憶體,研究人員可以將 A100 原需要 10 小時的雙精度模擬,縮短至 4 小時以內完成。在執行單精度的密集矩陣乘法作業時,高效能運算應用程式還可以利用 TF32,藉以提供高達 11 倍的輸送量。
對於擁有最大資料集的高效能運算應用程式,A100 80 GB 可採用一種名為 Quantum Espresso 的材質模擬,使額外記憶體的輸送量提升高達 2 倍。這種龐大的記憶體和前所未有的記憶體頻寬,讓 A100 80 GB 成為新一代工作負載的理想平台。
頂尖高效能運算應用程式
應用程式速度提升的幾何平均值 vs. P100:基準應用程式:Amber [PME-Cellulose_NVE]、Chroma [szscl21_24_128]、GROMACS [ADH Dodec]、MILC [Apex Medium]、NAMD [stmv_nve_cuda]、PyTorch (BERT 大型微調調諧器]、Quantum Espresso [AUSURF112-jR];Random Forest FP32 [make_blobs (160000 x 64:10)]、TensorFlow [ResNet-50]、VASP 6 [Si Huge] | GPU 節點採用雙插槽 CPU 並搭載 4 個 NVIDIA P100、V100 或 A100 GPU。
Quantum Espresso
Quantum Espresso measured using CNT10POR8 dataset, precision = FP64。
巨量資料分析基準測試 | 在 10TB 資料集進行 30 筆分析零售查詢、ETL、機器學習 (ML)、自然語言處理 (NLP) | V100 32 GB、RAPIDS/Dask | A100 40 GB 與 A100 80 GB、RAPIDS/Dask/BlazingSQL
資料科學家要能夠分析、視覺化,並將龐大資料集轉換成深入分析。但是,由於這些資料集分散在多個伺服器上,經常無法實行擴充解決方案。
使用 A100 的加速伺服器可提供處理這些工作負載所需的運算能力,包含每秒超過 2 TB (TB/秒) 的記憶體頻寬以及 NVIDIA® NVLink® 和 NVSwitch™ 的擴充能力。NVIDIA 資料中心平台結合了 InfiniBand、NVIDIA Magnum IO™ 以及 RAPIDS™ 開放原始碼函式庫套件,包括用於獲得 GPU 加速的資料分析,適用於 Apache Spark 的 RAPIDS 加速器,能夠以前所未有的效能與效率,加速這些龐大的工作負載。
在巨量資料分析基準測試中,A100 80 GB 比起 A100 40 GB 提供了高出 2 倍的深入分析,因此非常適合資料集急遽成長的新興工作負載。
BERT 大型推論
BERT 大型推論 | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = Int8,具稀疏性。
運用 MIG 的 A100 可將 GPU 加速的基礎架構使用率提升到最高。MIG 可將 A100 GPU 安全地分割成多達 7 個獨立的執行個體,讓多名使用者存取 GPU 加速功能。A100 40 GB 可讓每個 MIG 執行個體分配到多達 5 GB,而 A100 80 GB 因為記憶體容量增加,分配大小可加倍至 10 GB。
MIG 能與 Kubernetes、容器和以監視器為基礎的伺服器虛擬化搭配使用。MIG 讓基礎架構管理員能為每項作業提供適當規模的 GPU 及服務品質保障 (QoS),將加速運算資源的範圍延伸至每位使用者。
A100平台能為超過700種HPC應用項目及各種主要深度學習架構加速。
其使用範圍從桌上型電腦到伺服器,再至雲端服務,能提供大幅提升效能與節省成本的機會。

| A100 40GB PCIe | A100 80GB PCIe | |
|---|---|---|
| FP64 | 9.7 兆次浮點運算 | |
| FP64 Tensor 核心 | 19.5 兆次浮點運算 | |
| FP32 | 19.5 兆次浮點運算 | |
| Tensor Float 32 (TF32) | 156 兆次浮點運算 | 312 兆次浮點運算* | |
| BFLOAT16 Tensor 核心 | 312 兆次浮點運算 | 624 兆次浮點運算* | |
| FP16 Tensor 核心 | 312 兆次浮點運算 | 624 兆次浮點運算* | |
| INT8 Tensor 核心 | 624 兆次浮點運算 | 1248 兆次浮點運算* | |
| GPU 記憶體 | 40GB HBM2 | 80GB HBM2e |
| GPU 記憶體頻寬 | 每秒 1,555GB | 每秒 1,935GB |
| 最大散熱設計功耗 (TDP) | 250W | 300W |
| 多執行個體 GPU | 最多 7 個 MIG @ 5GB | 最多 7 個 MIG @ 10GB |
| 尺寸規格 | PCIe | |
| 互連技術 | NVIDIA® NVLink® 橋接器,可支援 2 個 GPU:每秒 600GB ** 第四代 PCIe:每秒 64GB |
|
| 伺服器選項 | 合作夥伴提供的 NVIDIA 認證系統™,搭載 1-8 個 GPU | |
未來展望



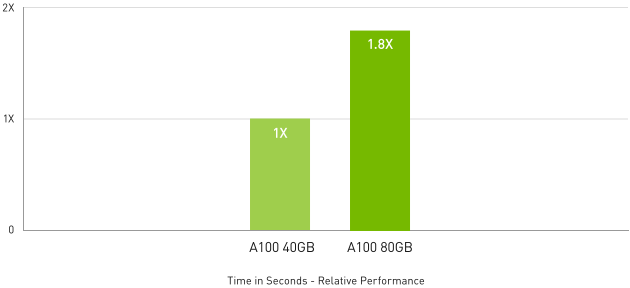

{kind=link}