語系 :

利用 NVIDIA H100 Tensor 核心 GPU,提供所有工作負載前所未有的效能、可擴充性和安全性。使用 NVIDIA® NVLink® Switch 系統,最高可連接 256 個 H100 來加速百萬兆級工作負載,此外還有專用的 Transformer Engine,可解決一兆參數語言模型。H100 所結合的技術創新,可加速大型語言模型速度,比前一代快上 30 倍,提供領先業界的對話式人工智慧。
適用於主流伺服器的 H100 提供 NVIDIA AI Enterprise 軟體套件的五年期訂閱加上企業支援,能以最高效能簡化人工智慧採用流程。如此一來,組織便能取得打造 H100 加速人工智慧工作流程所需的人工智慧框架和工具,例如人工智慧聊天機器人、推薦引擎、視覺人工智慧等。
混合專家演算法 (3950 億個參數)
H100 配備第四代 Tensor 核心和具有 FP8 精確度的 Transformer Engine,與前一代混合專家演算法 (MoE) 模型相比,訓練速度高達 9 倍。結合第四代 NVlink (每秒提供 900 GB GPU 對 GPU 互連)、NVLINK Switch 系統 (加速所有 GPU 跨節點集體通訊能力)、第五代 PCIe 和 NVIDIA Magnum IO™ 軟體,提供小型企業到大規模統一 GPU 叢集高效率可擴充性。
部署資料中心規模 H100 GPU,可提供優異效能,並且讓所有研究人員均能使用新一代百萬兆級高效能運算 (HPC) 和一兆參數人工智慧。
人工智慧使用各種不同的神經網路,解決各式各樣的商業挑戰。強大的人工智慧推論加速器,不只能提供最高效能,還能提供加速這些網路的各種功能。
H100 進一步擴展 NVIDIA 在推論領域的市場領先地位,此外還帶來多項進展,加速推論速度達 30 倍,並實現最低延遲時間。第四代 Tensor 核心加速了所有精確度,包括 FP64、TF32、FP32、FP16 和 INT8,而 Transformer Engine 則同時利用 FP8 和 FP16 減少記憶體使用量並提升效能,且仍然能夠維持大型語言模型的正確度。
Megatron 聊天機器人推論 (5,300 億個參數)
NVIDIA 資料中心平台持續提供超越摩爾定律的效能提升。H100 全新突破性人工智慧功能,進一步放大高效能運算搭配人工智慧強大功能,加速科學家和研究人員探索時間,解決全球最重要的挑戰。
H100 將雙精確度 Tensor 核心的每秒浮點運算次數 (FLOPS) 提高為 3 倍,提供高效能運算每秒 60 兆次浮點運算的 FP64 運算。融合人工智慧的高效能運算應用程式,能利用 H100 的 TF32 精確度,達到單精確度矩陣,乘法運算每秒 1 petaFLOP 浮點運算輸送量,而且無須變更程式碼。
HH100 也配備全新 DPX 指令,提供比 NVIDIA A100 Tensor 核心高出 7 倍的效能,而且與應用於 DNA 序列校準的 Smith-Waterman 等適用動態程式設計演算法的傳統雙插槽 CPU 伺服器相比,速度快 40 倍。
人工智慧應用程式開發時,資料分析通常耗費了大部分的時間。由於大型資料集分散在多個伺服器,僅使用 CPU 設備伺服器的橫向擴充解決方案,將因為缺乏可擴充運算效能而陷入困境。
使用 H100 的加速伺服器,除了提供運算強大功能外,每個 GPU 提供 每秒 3 TB 記憶體頻寬,並且可擴充使用 NVLink 和 NVSwitch,能夠支援大型資料集,高效能且大規模處理資料分析。將 NVIDIA 資料中心平台與 NVIDIA Quantum-2 Infiniband、Magnum IO 軟體、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™ 搭配使用,能以無與倫比的效能和效率水準加速這些巨大的工作負載。
IT 經理希望能將資料中心運算資源使用率提到最高 (包含峰值和平均值)。他們通常會針對使用的工作負載中適當大小的資源,採用運算動態重新設定。
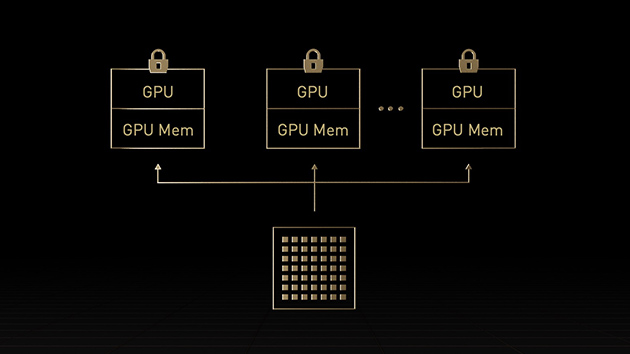
H100 中的第二代多執行個體 GPU (MIG),能夠安全分割每個 GPU 為多達七個獨立執行個體,最大化各個 GPU 的使用率。H100 提供機密運算支援,能夠安全進行端對端、多租用戶使用,是雲端服務供應商 (CSP) 環境的理想選擇。
使用多執行個體 GPU 的 H100 能夠讓基礎架構管理員標準化 GPU 加速基礎架構,同時具備更大彈性佈建更細緻的 GPU 資源,安全地提供開發人員合適的加速運算功能,並最佳化所有 GPU 資源使用。
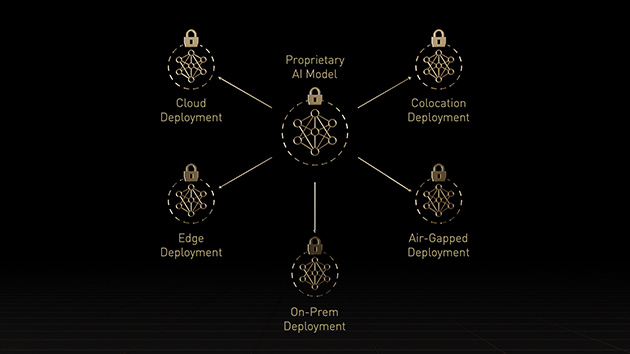
現今的機密運算解決方案以 CPU 為基礎,對人工智慧和高效能運算等運算密集的工作負載來說限制過大。NVIDIA 機密運算是 NVIDIA Hopper™ 架構的內建安全功能,讓 H100 成為全球第一個具有機密運算功能的加速器。使用者能夠利用無可匹敵的 H100 GPU 加速能力,同時保護使用者資料和應用程式的機密與完整性。NVIDIA H100 GPU 建立了以硬碟為基礎的可信任執行環境 (TEE),保護並隔離在單一 H100 GPU、節點中多個 H100 GPU 或個別多執行個體 GPU 的執行個體上,執行的所有工作負載。GPU 加速的應用程式無須修改就能在可信任執行環境中執行,且不必分割。使用者可以結合使用在人工智慧與高效能運算的 NVIDIA 軟體強大功能,以及 NVIDIA 機密運算提供的硬體信任根安全性。
NVIDIA H100 CNX 在單一獨特平台上,結合 H100 的強大功能與 NVIDIA ConnectX®-7 智慧網路介面卡 (SmartNIC) 的進階網路功能。上述結合為 GPU 支援且 IO 密集的工作負載,提供無與倫比的效能,例如,企業資料中心的分散式人工智慧訓練,以及邊緣端 5G 處理。
Hopper Tensor 核心 GPU 將驅動 NVIDIA Grace Hopper CPU+GPU 架構,專為 TB 級加速運算打造,並為大模型人工智慧和高效能運算提供高出 10 倍的效能。NVIDIA Grace CPU 運用 Arm® 架構的彈性,專為加速運算需求而從頭打造 CPU 和伺服器架構。Hopper GPU 搭配 Grace CPU 使用 NVIDIA 超高速晶片對晶片互連技術,提供每秒 900GB 頻寬,比第五代 PCIe 快 7 倍。與現今最快速的伺服器相比,此創新設計可提供高達 30 倍的彙總系統記憶體頻寬,且能為執行數 TB 資料的應用程式,提供高達 10 倍的效能。

| FP64 | 26 TFLOPS |
| FP64 Tensor 核心 | 51 TFLOPS |
| FP32 | 51 TFLOPS |
| TF32 Tensor 核心 | 756 TFLOPS* |
| BFLOAT16 Tensor 核心 | 1,513 TFLOPS* |
| FP16 Tensor 核心 | 1,513 TFLOPS* |
| FP8 Tensor 核心 | 3,026 TFLOPS* |
| INT8 Tensor 核心 | 3,026 TOPS* |
| GPU 記憶體 | 80GB |
| GPU 記憶體頻寬 | 2TB/s |
| 解碼器 | 7 NVDEC 7 JPEG |
| 最大散熱設計功耗 (TDP) | 300-350W (可設定) |
| 多執行個體 GPU | 最多 7 個 10GB 的多執行個體 GPU |
| 尺寸規格 | PCIe 雙插槽氣冷 |
| 互連技術 | NVLink:每秒600GB,第5代PCIe:每秒128GB |
| 伺服器選項 | NVIDIA 認證系統™,搭載 1 到 8 個 GPU |
| NVIDIA AI Entrprise | 包含 |
* 上述資訊以稀疏性顯示。若不含稀疏性,需將規格減少一半
未來展望









{kind=link}